

Flujos para visualización de datos con IA
La adopción de herramientas de IA generativa está modificando la manera de trabajar sobre procesos de análisis y visualización de datos en la que se viene trabajando desde hace décadas.
El flujo de trabajo tradicional
Desde que se pasiviza el uso de la planilla de cálculo Lotus, y luego Excel en entorno windows, el proceso estándar para producir reportes con visualización de datos siguió una secuencia relativamente estable.
- La recopilación y ordenamiento de datos en una planilla de cálculo maestra de frecuencias absolutas.
- La extracción de subconjuntos estadísticos en tablas condensadas, diseñadas específicamente para que las frecuencias relativas sean graficadas.
- Selección manual de rangos de datos para insertar gráficos —de barras, circulares, de líneas— en la misma planilla.
- La exportación de esas visualizaciones a un procesador de texto para construir el reporte final en formato imprimible.
Este flujo, aunque funcional, concentraba una proporción significativa del tiempo de trabajo en la construcción de la visualización, no en su interpretación. Cada actualización de datos requería repetir parte del proceso. Cada nuevo reporte implicaba reconfigurar los rangos, los formatos, los gráficos.
Era un flujo eficiente para su época. También era invisible como problema, precisamente porque funcionaba.
El flujo emergente con IA generativa
El rediseño del proceso se inició con una premisa operativa simple: delegar la construcción de las visualizaciones al modelo de lenguaje y reservar el tiempo humano para el análisis de los resultados.
El procedimiento adoptado siguió estos pasos:
- Preparación del archivo de datos en formato CSV a partir de la planilla maestra
- Carga del archivo en una sesión con Gemini (modelo de lenguaje con capacidad de razonamiento extendido) para que “entendiera” la fuente de información
- Formulación del requerimiento: generar una aplicación web que funcione como tablero dinámico, con pestañas desplegables, visualizaciones múltiples y opción de exportación a PDF
- Iteración sobre el código generado mediante refinamientos sucesivos: ajuste de estilos, corrección de lecturas erróneas, incorporación de nuevas variables
- Copiado del código HTML en un archivo local y apertura en navegador
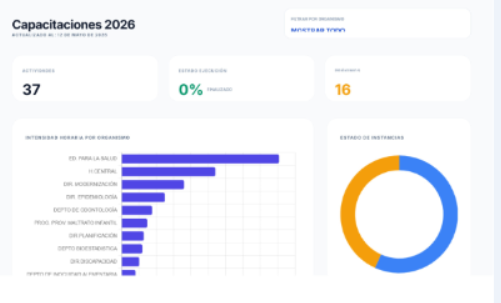
El resultado fue un tablero funcional que permitía explorar los datos sin intervención adicional de software especializado. La aplicación no requiere instalación, corre en cualquier navegador y puede compartirse o exportarse.
Los errores de datos como variable crítica
El hallazgo más relevante del proceso no fue la herramienta. Fue lo que la herramienta expuso.
Durante la iteración, varias visualizaciones presentaban valores inconsistentes: categorías que aparecían vacías, conteos que no coincidían con el total esperado, agrupaciones que omitían registros. El diagnóstico inicial apuntaba a limitaciones o inconsistencias del modelo, pero diagnóstico correcto (indicado por Antigravity) señalaba como fuente de problemas al propio archivo de datos.
El archivo CSV contenía errores acumulados que el flujo de trabajo anterior nunca había detectado: nombres con alguna letra en mayusculas (una letra adicional, un acento) que al ser un archivo de texto y no de planilla de cálculo, el sistema interpreta como valores distintos y otros errores de revisión como columnas con codificaciones mixtas, donde convivían valores numéricos y alfanuméricos sin criterio uniforme
En el flujo tradicional, usualmente estos errores no influyen demasiado. Los gráficos se generaban, los totales cuadraban dentro de lo esperable, o se editaban y nadie señalaba inconsistencias porque el proceso no tenía un mecanismo de validación explícito.
La IA generativa, al intentar clasificar y visualizar los datos con precisión, hizo visible lo que el proceso anterior dejaba opaco. No como función de auditoría , no está diseñada para eso, sino como efecto colateral de su propia lógica de interpretación.
Una vez corregidos los errores en el archivo fuente, todas las visualizaciones se resolvieron correctamente.
Alcances y limitaciones
Esta a aplicacion no reemplaza a las plataformas comerciales de inteligencia de negocios, ni siquiera a las planillas de cálculo.
Lo que ofrece el flujo descripto es distinto: velocidad de implementación, autonomía técnica sin conocimientos de programación, costo cero de infraestructura, pero por sobre todo ajustarse a una adecuación a necesidades acotadas.
Es una solución apropiada cuando el volumen de datos es manejable, la frecuencia de actualización es periódica , no en tiempo real, y el objetivo es producir un reporte o tablero de uso interno sin requerimientos de escalabilidad.
La condición más crítica para replicar el proceso es la calidad del archivo de entrada. Un CSV con inconsistencias de codificación, valores mixtos o categorías sin estandarizar producirá visualizaciones incorrectas independientemente de la capacidad del modelo. La preparación del dato es, en este flujo, la competencia central.
Implicancias para el trabajo con datos
El rediseño descripto desplaza el eje del trabajo: del tiempo dedicado a construir visualizaciones al tiempo dedicado a interpretar lo que esas visualizaciones muestran. Este desplazamiento no es menor. En contextos donde el análisis de datos forma parte de una práctica profesional recurrente (salud, educación, gestión institucional), la reducción del tiempo de construcción puede traducirse en mayor profundidad analítica o en mayor frecuencia de producción de reportes.
La segunda implicancia es menos visible pero más estructural: la calidad de los datos de entrada emerge como competencia crítica. No alcanza con saber usar la herramienta. Es necesario garantizar que el archivo que la alimenta sea consistente, homogéneo y libre de errores de codificación. Esta competencia —validación y estandarización de datos— no es nueva, pero adquiere mayor relevancia cuando el modelo amplifica cualquier inconsistencia al intentar clasificar con precisión, y ésta es una competencia humana.
La IA generativa no mejora datos deficientes. Los hace visibles.
Muy bueno el análisis, realmente debe estar ocurriendo eso y hay que contemplarlo. (bien realista y concreto).