

TurboQuant: Comprimir sin olvidar
Cada vez que un modelo de lenguaje como ChatGPT o Gemini responde un mensaje, necesita recordar todo lo que se dijo antes en la conversación. Esa memoria se almacena en una estructura llamada caché KV (key-value), que crece con cada nuevo mensaje. El problema es que, a medida que la conversación avanza, esta memoria consume cada vez más recursos: más espacio en servidores especializados, más energía y más tiempo de procesamiento. En conversaciones largas, este crecimiento puede convertirse en el principal cuello de botella para la velocidad y el costo de operación de estos sistemas.
Un algoritmo que nace de la investigación
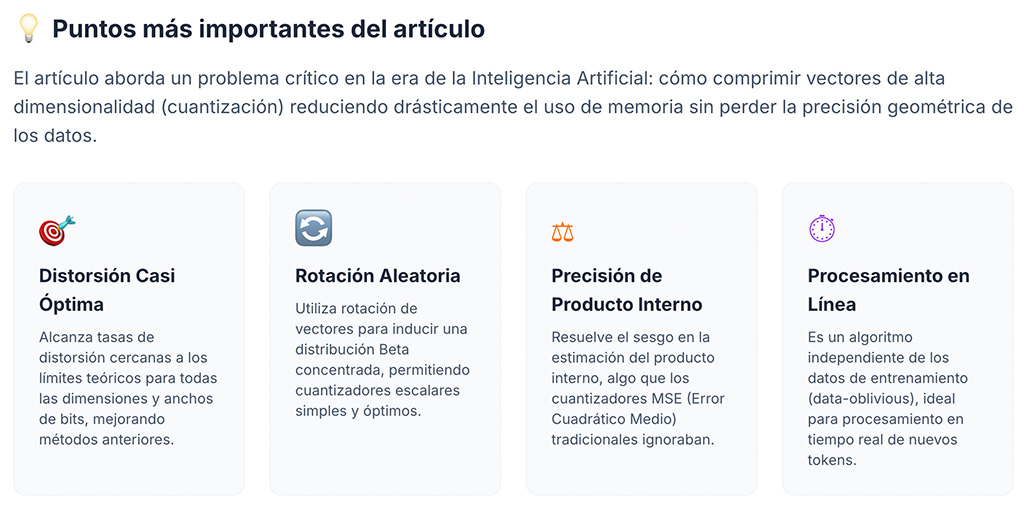
TurboQuant es un algoritmo de cuantización vectorial desarrollado por los investigadores Amir Zandieh, Majid Daliri, Majid Hadian y Vahab Mirrokni, del equipo de Google y la Universidad de Nueva York. La cuantización, en términos simples, consiste en representar valores numéricos de alta precisión con menos bits, como si se redondearan de forma inteligente. Lo que distingue a TurboQuant de otras técnicas es que logra esta compresión sin necesidad de analizar previamente los datos: funciona "al vuelo", lo que lo hace ideal para aplicaciones en tiempo real como las conversaciones con modelos de lenguaje.
De la geometría a la compresión
El algoritmo funciona en dos etapas. Primero, aplica una rotación aleatoria a los vectores que representan la memoria del modelo. Esta rotación distribuye la información de manera uniforme, como si se barajaran las cartas antes de repartirlas, lo que permite comprimir cada valor por separado sin perder la relación entre ellos. Luego, aplica una segunda capa de compresión sobre el error residual —la pequeña diferencia entre el valor original y el comprimido— para que las operaciones matemáticas que el modelo necesita hacer sigan siendo precisas.
Los resultados experimentales son notables: con solo 3,5 bits por valor (frente a los 16 bits habituales), el modelo mantiene la misma calidad de respuesta que sin compresión. Incluso con 2,5 bits, la degradación es mínima. Esto implica una reducción de memoria superior a cuatro veces.
Tomar notas en lugar de releer todo
Una forma de entender lo que hace TurboQuant es imaginar a un asistente que, en lugar de releer la transcripción completa de una reunión cada vez que necesita responder una pregunta, toma notas extremadamente precisas que ocupan mucho menos espacio. Esas notas capturan la esencia de cada intervención con una fidelidad tan alta que, en la práctica, la diferencia con el texto completo resulta imperceptible.
Expectativas y realidades
Este tipo de avances ha generado expectativas significativas. Google, como origen de la investigación, ya lo considera una pieza clave para manejar ventanas de contexto masivas en sus modelos. En el ecosistema de código abierto, proyectos como llama.cpp y vLLM están explorando integraciones basadas en los mismos principios matemáticos. Otras empresas, como OpenAI y DeepSeek, abordan el mismo problema por caminos diferentes pero complementarios.
Sin embargo, conviene ser precisos: TurboQuant no hará posible que un modelo de lenguaje completo funcione desde un teléfono móvil o una laptop. Los grandes modelos seguirán requiriendo servidores especializados. Lo que sí permite es reducir significativamente los costos de procesamiento y ofrecer respuestas más rápidas, especialmente en conversaciones largas. Un avance que nace, como tantos otros, de un artículo de investigación.
Del laboratorio de investigación a la producción comercial
TurboQuant ilustra cómo la investigación básica —en este caso, en teoría de la información y geometría de alta dimensión— puede traducirse en mejoras concretas para los sistemas de inteligencia artificial que millones de personas usan a diario. Para quienes seguimos el campo desde la academia, es un recordatorio de que detrás de cada mejora visible hay un paper, un equipo y una idea matemática que lo hizo posible.
Resumen técnico
Haga clic en la siguiente imagen para ver toda la información.
Infografía generada por Gemini
Fuentes consultadas
DeepSeek-AI. (2024). DeepSeek-V3 Technical Report. GitHub. https://github.com/deepseek-ai/DeepSeek-V3
Gao, J., & Long, C. (2024). RaBitQ: 1-Bit Vector Quantization for High-dimensional Vector Search. En Proceedings of the 2024 International Conference on Management of Data (SIGMOD ’24). Association for Computing Machinery. https://doi.org/10.1145/3626246.3653372
Ggerganov, G. (2026). llama.cpp: Port of Facebook's LLaMA model in C/C++ (Pull Request #21038 - attn-rot). GitHub. https://github.com/ggml-org/llama.cpp
Han, I., Kacham, P., Karbasi, A., Mirrokni, V., & Zandieh, A. (2025). PolarQuant: Quantizing KV Caches with Polar Transformation. arXiv. https://arxiv.org/abs/2502.02617
ParaMind2025. (2026). IsoQuant: Hardware-Aligned SO(4) Isoclinic Rotations for LLM KV-Cache Compression. arXiv. https://arxiv.org/abs/2603.28430
Scrya-com. (2026). RotorQuant: KV Cache Compression via Block-Diagonal Rotation. GitHub. https://github.com/scrya-com/rotorquant
TheTom. (2026). TurboQuant+: Advanced implementations and system optimizations. GitHub. https://github.com/TheTom/turboquant_plus
Zandieh, A., Daliri, M., & Han, I. (2024). QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead. arXiv. https://arxiv.org/abs/2406.03482
Zandieh, A., Daliri, M., Hadian, M., & Mirrokni, V. (2025). TurboQuant: Online vector quantization with near-optimal distortion rate. arXiv preprint arXiv:2504.19874. https://arxiv.org/abs/2504.19874
Transparencia en el uso de la IA
Investigación con Gemini y Perplexity.
Imágenes de síntesis elaboradas con Gemini.
Imágenes ilustrativas elaboradas con Gemini NanoBanana 2 y ChatGPT.
Artículo elaborado con asistencia de Claude (análisis y síntesis del paper fuente, redacción).
El artículo fue revisado y completado por el autor.